데이터 테이블의 관계
- 1:1
- 1 : n
- n : n- 조인 걸면 안됨
조인의 종류 5가지
1. 카타시안의 곱
-n:n 형태
-데이터를 복제하는 용도로 사용함
-데이터베이스 제품에서 제공되는 함수가 없는 경우에는
카타시안의 곱을 활용해서 데이터를 2배수 3배수 복제하고
컬럼레벨에 있는 값을 로우레벨에 출력하는것이 가능함
2. 등가조인 - equals join - natural join - inner join
교집합
where 절이 없다
PK와 FK연결이 필요없다->자동
직관적이다.
양쪽 테이블에 모두 존재하는것만 조회된다.
둘중 한쪽에만 있는것을 조회하고싶다면
emp=14사원
dept =4가지
결과의 row수는 14
결과는 56->카타시안의 곱 ->나올 수 있는 부서의 모든 종류가 다 출력

3. non-equal 조인
between A and B
In - or- 이거나, 또는
is nul, is not null
4.outer join
합집합
너는 있는데 나는 없어 너를 널로 하더라도 보여주세요.

5. self join
나 자신과 1 : 1관계 혹은 1 : n 의 관계에 있다면 self join이다.
같은 이름의 테이블을 두번 적었다고해서 self조인이 아니다.

부서와 사원-> 1 : n 의 관계...?
집합의 정의에 따라서 관계형태는 바뀔 수 있다.
부서와 사원은 n : n 관계
테이블을 그대로 출력하는 경우는 99% 없다.
부서집합 정의
현재근무한 부서를 관리하는 집합이 아니라
근무한 이력을 관리하는 부서집합
부서와 사원 : n : n관계
이력관리를 하는 집합이 필요하다.
잔여 포인트를 기록했다.
이것이 이력관리..?
NO
언제 어디서 포인트를 사용했는지를 알아야 이력관리이다.
이런것을 충족시킬려면 일대일 관계로 데이터 관리해야된다.
네추럴 조인을 해야된다...

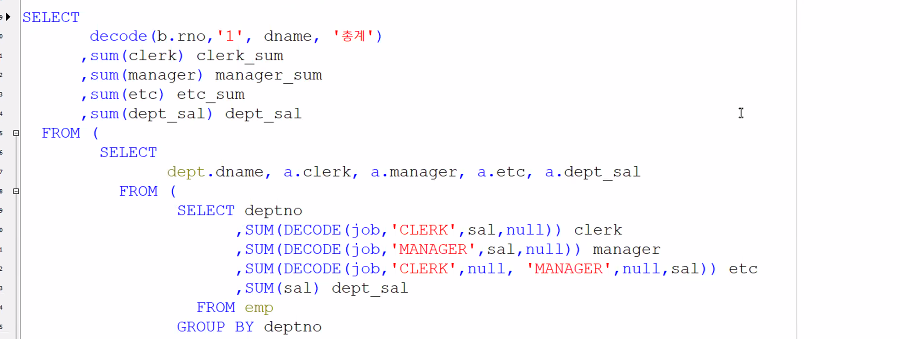
b를 왜 추가했나?
1
2
이런식의 표를 추가해서
1일때는 부서들
2일때는 총계가 나오도록 하기위해
그룹바이 절에다가 2인경우를 집어넣어서 총계를 구하려고

그룹바이 의미가 없다. 인덱스 없다. 이름에는
있으나 없으나 결과가 같다.
컬럼을 늘리는 방법

로우를 늘리는 방법

여기에 총계를 붙일 수 있을까? 안된다. 타입이 다르기 때문이다.
union all은
중복을 제거하지 않는다.
두집합 그대로 합친다.
순서를 따지지 않고 합치는 것이다.
같은 타입끼리만 가능함. union도 마찬가지.
정렬이 일어나지 않음
속도는 빠르다.
union은
중복을 제거 한다. 2차 가공을 하고 있다. 같은게 있는지 비교한다.
중복을 제거함 - 두집합을 비교한 다음 합침. 속도 차이가 발생함.
순서를 따지게됨 - 왜냐면 두 집합을 스캔해서 값을 비교한다는 의미이니까
union all 을 사용한 경우와 결과가 같을 수 있지만 정렬 순서는 다를 수 있다.
왜냐하면 두 집합을 각각 스캔하고 비교한 후 결과값을 출력하니까.
Hash Join방식으로 중복을 제거함
정렬이 일어남
기본적으로 정렬이 일어나면 2차 가공이 일어나는 것으로 생각.
속도는 느리다.

넘버타입인 deptno와 바차타입 dname은 같이 붙일 수 없다. 타입이 다르다.


emp 테이블에서는 deptno는 PK가 아니다. 그런데 dept테이블에서는 pk라 dname이 의존하고있다.
deptno에 dname이 의존한다? 제 3 정규화 위배이다.
정규화
제3정규화
행 함수 종속이 발생한다고 한다. 이를 제거하는 것이 제 3정규화.
https://mjn5027.tistory.com/46
[ Database ] 제 1정규화, 제 2정규화, 제 3정규화
정규화란? 데이터베이스의 데이터들을 최대한 중복을 제거하여 이상 현상 ( Anomaly ) 을 방지하기 위한 기술이다. 여기서 말하는 이상현상은 세 가지가 있는데 간략하게 설명하면 다음과 같
mjn5027.tistory.com
총계 계산을 위한 컬럼은 샐러리다.
그런데

이렇게하면 총합 구할 수 없다.

로우가 둘인 dual테이블을 만들어서(더미 테이블) 인라인뷰에 넣으면 이렇게 나온다.
왜 더미 테이블을 사용하는지의 이유가 된다.
1. 같은 테이블을 절대로 두번씩 읽지 않는다.
-경우의 수가 너무 많으니까
2. 같은 튜플에서 같은 컬럼의 값이 두번씩 사용 되어야 한다.
한번은 부서별 잡별로 계산하는데 필요하고
두번은 총계에서 잡별로 계산하는데 필요하다.
그래서 더미테이블을 사용하였다.

나머지 빈자리는 null로 채워졌다.
잡이 클락이면 샐러리표시 아니면 널
이걸 따로따로 보고싶지 않다. 합쳐서 보고싶다. sum을 사용한다.

썸을 사용해서 총합을 구했다.

그룹바이 쓰기위해 deptno를 가져왔다.
그런데 dname별로 그룹바이 하고싶다.

그런데 emp안에는 dname이 없다.

dname으로 그룹바이를 하기위해서는 emp, dept둘다써준다.

그런데 그룹바이 밑에는 where를 조건으로 쓸 수 없다.
having절을 사용해야한다.

이런식으로 having절 사용한다.


dept에 dname이랑 a 집합에있는 클락 매니저 등등 세가지를 컬럼으로 한다.
a집합의 deptno(emp의 deptno)와 dept의 deptno가 같다.

로우를 컬럼으로 바꾸고 싶다.
더미 테이블로 멀티플 해준다.
emp전체와 dept전체를 조인 조건으로 사용하는 것 보다는
emp집합에 그룹바이를 통해서 1차 가공을 하여 경우의 수를 3건으로 만든다.
문제1
소계와 총계 연습문제 1다음 t_orderbasket 테이블에서 분석용 함수를 사용하지 않고 각 날짜별로
총 몇개의 물건이 얼마만큼 팔렸으며 매출액은 어떻게 되는지 알고 싶다.
어떻게 소계와 합계를 구할 것인가?



emp는 아무 테이블이나 와도 상관없다.
select 1 from dual
union all
select 2 from dual
형광펜 부분은 위의 더미 테이블이랑 같은 꼴이다.
총계를 위해서
문제2
날짜별 판매개수와 매출액이 아닌 날짜와 판매물품의
구분을 같이 출력하되 마지막에 판매 물품에 대한 구분을 넣어서 각각의
소계와 합계를 출력해 본다.



|| 옆에 붙여주기
그룹바이로 정렬해줬다.

로우넘이 1일때 날짜
2일때 총계
3일때 소계
그러면 로우로 123나오겠지
날짜
총계
소계
이렇게
그옆에 gubun붙여주기


ㅇ
ㅇ
ㅇ
ROLLUP은
GROUP BY절에 사용되며 GROUP의 순서에 의한 멀티 레벨의 소계 및 합계를 구해주는 함수이다.
ROLLUP이나 CUBE를 다루면서는 GROUPPING()함수를 종종 볼수 있는데 이것은 모든
값에 대한 SET을 나타내는 NULL값과 컬럼의 NULL값을 구분하는데 쓰여진다.
즉 GROUPPING()은 모든 값의 SET을 표현함에 있어서 NULL이면 1을 아니면 0을 RETURN함
으로써 소계와 총계부분을 나타내 주는 역할을 한다.

rownum


인라인뷰

rno를 where안에 넣을 수 없다.
그래서 인라인뷰로 넣어준다.
인라인뷰 안에 쓴 rno를 밖에서 조건절에 쓸 수 있다.
서브쿼리
-select문이 where절 에 오는것을 말한다.
from절에는 집합이 올 수 있다.
select문도 올수있다--->인라인뷰

서브쿼리 연습문제
1.temp에서 연봉이 가장 많은 직원의 row를 찾아서 이 금액과 동일한 금액을
받는 직원의 사번과 성명을 출력하시오.
2.temp의 자료를 이용하여 salary의 평균을 구하고 이보다 큰 금액을 salary로
받는 직원의 사번과 성명, 연봉을 보여주시오.
3.temp의 직원 중 인천에 근무하는 직원의 사번과 성명을 읽어오는 SQL을 서브
쿼리를 이용해 만들어보시오.
4.tcom에 연봉 외에 커미션을 받는 직원의 사번이 보관되어 있다.
이 정보를 서브쿼리로 select하여 부서 명칭별로 커미션을 받는
인원수를 세는 문장을 만들어 보시오.
1번.

2번

3번

4.

in함수는 앞에 있는 컬럼이 인 안에 집합이랑 같을때 반환한다.

dept_name을 출력해라
temp랑 tdept랑 두 테이블에서 코드 같을때
그리고 emp_id와 in안에 있는 셀렉트문의 값들이 같을때

심화문제
tdept에서 부서코드와 boss_id를 읽어서 이 두개 컬럼이 temp의 부서코드와
사번에 일치하는 사람의 사번과 성명을 읽어오는 쿼리를 만들어보자.

RDBM제품
1. 테이블 갯수가 많아진다.
2. 업무에 대한 복잡도에 따라 복합키가 많이 발생하게 된다.
컬럼 두개가 모여야 PK가 될수있다는데?!?!?!
테이블에 기본키가 3개 이상인 경우가 있다.
업무에 대한 복잡도가 증가함에 따라 테이블의 관계가 depth도 깊어지고
관계형태가 n:n인경우 업무에 대한 정의가 덜 된 경우임
두 집합 사이에서 1:n으로 만들어주는 행위 엔티티가 필요하다.
예) 회원집합과 도서집합 (n:n) - 대여 행위 집합
----여러 사람이서 도서관의 많은 책을 공유함
회원과 상품 - 쿠팡, 11번가
학생집합과 교과목집합
AK(인조키)
AK는 PK가 되지못한애다...?
AK를 사용하면 인덱스의 크기가 작아짐
의미상의 주어는 아니다.
부모테이블이 누구인지 드러나지 않는다.
join시에 AK를 사용할 수 있나요?
outer조인을 걸면
성적표는 수강신청 기준으로 나가야 된다.
수강신청이라는 행위가지고 안내하고 성적도 내야한다.
select
학생, 학생이름, 교과목, 강의실번호, 수강신청, 출석점수, 수강신청, 평가점수
from 학생, 교과목, 수강신청
where 학생, 학번 = 수강신청, 학번
and 교과목, 과목코드 = 수강신청, 과목코드
FK(외래키)들이 조인에 있어서 직접적인 대상이 되는 컬럼이다.
AK는 조인 안된다.
상품 주문시에....(가정)
주문자 - 회원집합
상품명 - 상품집합
주문일자 - 주문집합
배송일자 - 배송집합
가격 - 상품집합이나 단가집합(따로관리할경우)
select
회원.회원명, 상품.상품명, 주문.주문일자, 단가.가격
from 회원, 상품, 주문
where 회원.회원코드 = 주문.회원코드---조인조건1
and 상품.상품코드 = 주문.상품코드------조인조건2
and 상품.상품코드 = 단가.상품코드
--집합이 3개이면 조인조건은 n-1개가 필요함
--집합이 3~4개는 있어야 고객이 원하는 정보를 보여줄 수 있다.
inner join- 실제 주문자가 거래한 내용을 확인 가능함 - 가장 일반적이다.

두개 이상의 테이블 조인시에 먼저 읽는 테이블이 있고
나중에 읽는 테이블이 있다.
실행계획을 보는 방법
ctrl + E
안쪽에서 바깥쪽으로
실행계획을 세우는 기준은 all_rows
hash join방식
각각의 테이블을 풀 스캔하고 조건을 비교하면서 만족하는 로우값을 꺼내서 메모리에 올림
Nested Loop Join방식
먼저 한 테이블을 읽고 (드라이브 함) 조건에 있는 컬럼을 기준으로 상대 테이블의 컬럼값을
비교해가면서 조건을 수렴하는 결과를 메모리에 올림
select /*+rule*/
emp.empno, emp,ename, dept.dname
from emp, dept
where emp.deptno = dept.deptno
'학원수업 > 1월' 카테고리의 다른 글
| 01/12 국비학원 34회차 오라클 수업(PL/SQL) (0) | 2023.01.12 |
|---|---|
| 01/11 국비학원 33회차 오라클수업 (0) | 2023.01.11 |
| 01/09 국비학원 31회차 오라클수업(Join) (0) | 2023.01.09 |
| 01/06 국비학원 30회차 오라클수업 (0) | 2023.01.06 |
| 오라클 시험 오답노트(ERWin) (0) | 2023.01.06 |




댓글